TensorFlow로 디자인시스템 만들기

이 블로그 포스팅은 저에게 매우 의미 있는 순간입니다. 저는 지난해부터 생활코딩에서 진행한 머신러닝 야학에서 머신러닝에 처음 관심갖기 시작했습니다. 사실 그리 깊게 공부한 것도 아니었지만, Youtube에서 #madeWithTFJS 캠페인을 통해서 엔지니어가 아닌 참여자들도 멋진 웹기반 AI제품들을 만드는 것에 깊은 인상을 받았고, 저도 그들처럼 TensorFlow를 사용해서 제가 현재 겪고있는 프로덕트 디자인의 문제들을 해결할 수 있는 작은 솔루션을 만들어 보기로 결심했습니다.
그 당시 저는 LINE에서 일하고 있었는데, 기본적으로 제 업무는 디자이너와 엔지니어가 사용하는 글로벌 디자인 시스템을 만드는 것이었습니다.
디자인 시스템은 디자이너와 엔지니어의 공통의 시각적 언어이며, 요즘은 Google처럼 글로벌 대기업들 뿐 아니라 작은 스타트업에서도 쉽게 만들어 사용할 수 있을 정도로 보편화됐습니다.
하지만 여전히 디자인 시스템은 큰 장애물을 가지고 있습니다. 디자인 시스템에 더 많은 컴포넌트와 패턴들이 포함할수록, 이것이 훨씬 더 사용하기 복잡해진다는 것 입니다 그래서 그동안 프로젝트에서 디자인 시스템을 잘 사용하던 팀들 조차도 점점 복잡해지는 라이브러리 때문에 애를 먹는 경우가 종종 발생합니다.
그래서 저는 컴퓨터가 사람 대신에 수많은 디자인 요소들을 반복해서 학습하고, 마치 오타를 찾아주는 것처럼 디자이너의 화면에서 자동으로 디자인 시스템의 규칙을 추천해주는 어시스턴트를 만들면 이런 문제가 해결될 수 있겠다고 생각했고, 프로젝트를 시작했습니다.
프로젝트 아이디어와 데모
프로젝트의 기본 아이디어는 TensorFlow의 Custom object detection API를 사용해서 브라우저에서 UI요소들을 자동으로 검출하는 것 입니다. 이런 간단한 아이디어에도 불구하고, Mobbin, SelectStar, 그리고 Zeplin과 같은 훌륭한 회사들이 이 프로젝트에 관심을 갖고 지원을 해준 덕분에 아래와 같이 Zeplin-ML이라는 간단한 웹애플리케이션을 만들어서 출시했습니다. 도와주신 분들께 진심으로 감사드립니다.
Zeplin-ML은 여러분의 스크린 디자인들에서 UI객체를 찾아주는 기능을 제공하며, 그것을 비교하기 쉽게 컴포넌트 라이브러리 화면들도 제공합니다. 아래의 Youtube에서 보다 자세한 내용을 확인하세요!
추가로, 두 화면의 자동 비교 기능을 조만간 추가할 계획이니 이 프로젝트의 watch 버튼을 눌러서 주시해주세요.
프로젝트의 상세 진행 과정
다음으로는 이번 Zeplin-ML을 만들면서 쌓은 노하우를 포스팅합니다. 개인적인 경험일 뿐이지만, 저처럼 TensorFlow JS를 이용해서 재미있는 서비스를 만드실 분들에게 참고가 됐으면 좋겠습니다.
1.데이터 수집: Mobbin
싱가포르의 디자인 스타트업인 Mobbin은 디자이너들이 다양한 레퍼런스를 찾기을 때 이용하는 디자인 전문 검색 서비스를 제공합니다. Mobbin은 현재는 약 50,000장이 넘는 다양하고 균일한 품질의 iOS 또는 Android 스크린샷을 저장하고 있으며, “회원 가입”, “텍스트 버튼” 처럼 디자이너가 원하는 패턴 또는 UI요소로 검색해서 다양한 영감을 받을 수 있습니다.
이런 균일하고, 다양한 품질의 Mobbin의 데이터를 이 프로젝트에 사용할 수 있다면 아주 좋은 성능의 ML 모델을 만들 수 있을 것이라 확신했고, 조심스럽게 Mobbin에게 이 프로젝트에 기여해줄 수 있는지를 문의했습니다.
운이 좋게도 Mobbin과 몇차례 화상 회의와 프리젠테이션을 할 수 있었고, 마침 그들도 스크린샷에 Auto-tagging 을 하는 기능에 관심이 있었기 때문에 이 작은 프로젝트가 그들의 데이터 일부를 가져다 사용하는 것을 허락해습니다.
이후에 저는 Grida에서 제공하는 UI-Crawler를 사용해서 Mobbin 서비스를 크롤링했고, 약 12,000 장의 고품질의 iOS 스크린샷 이미지를 확보했습니다.
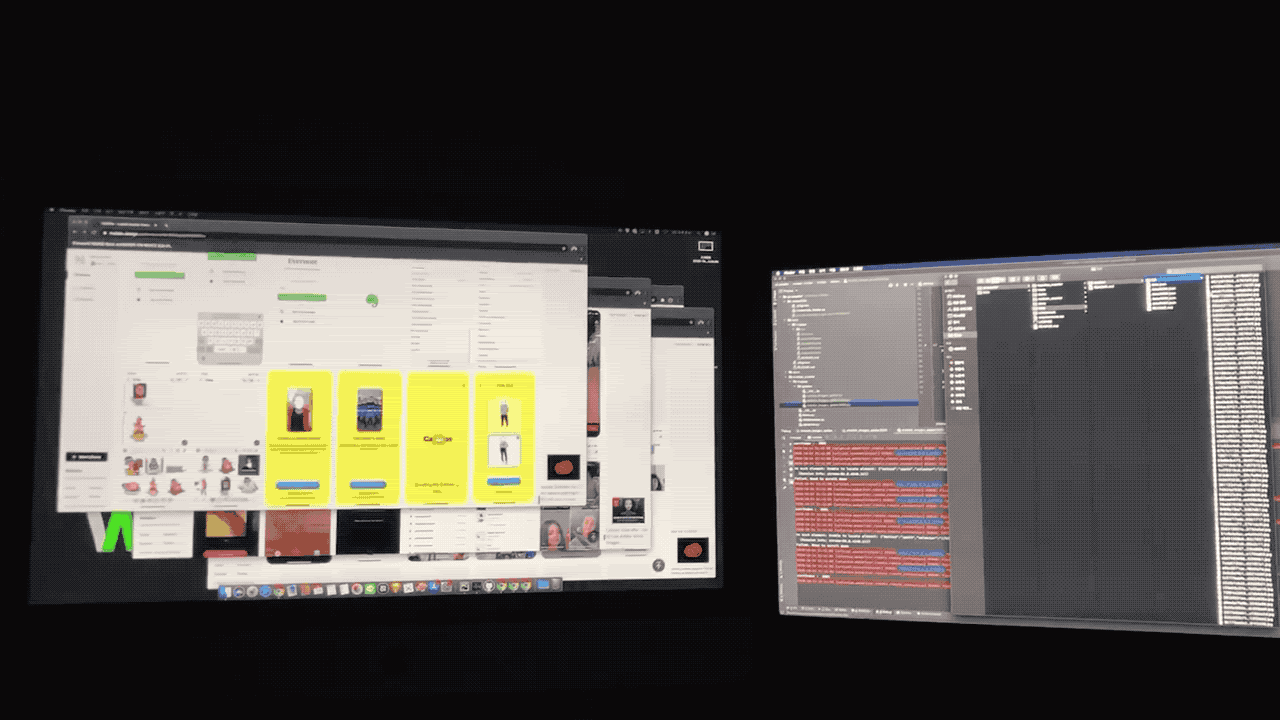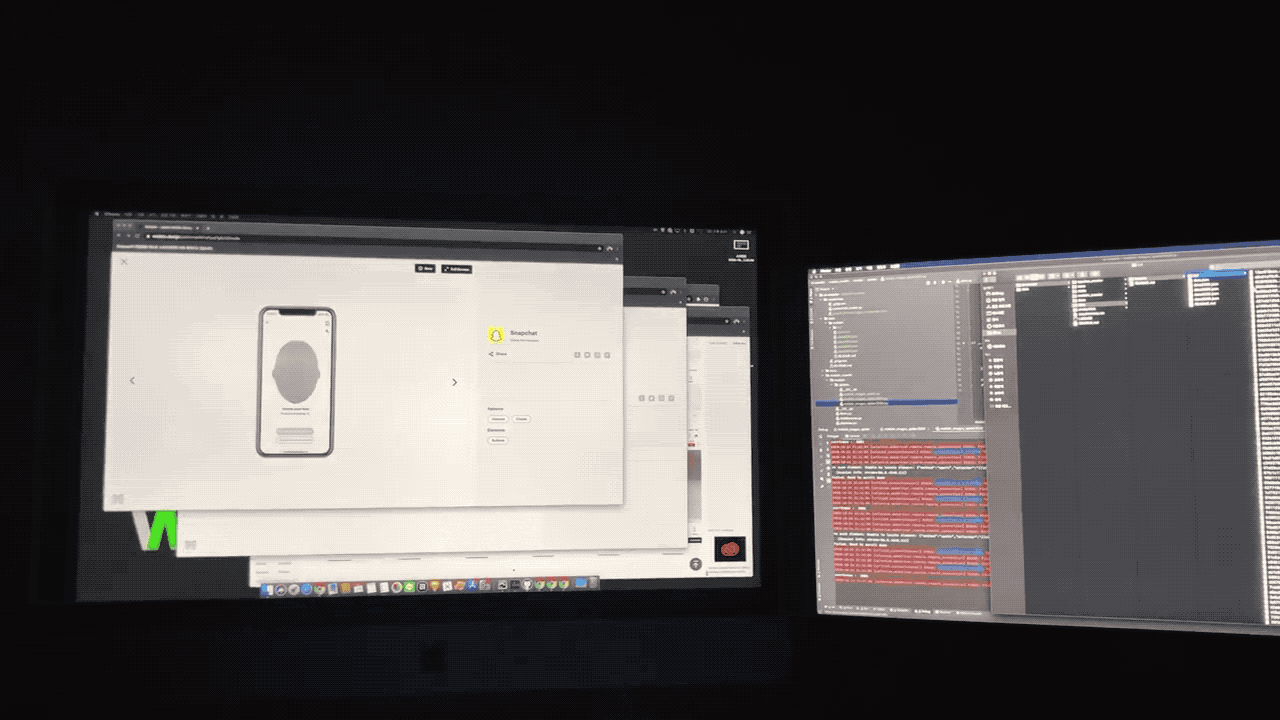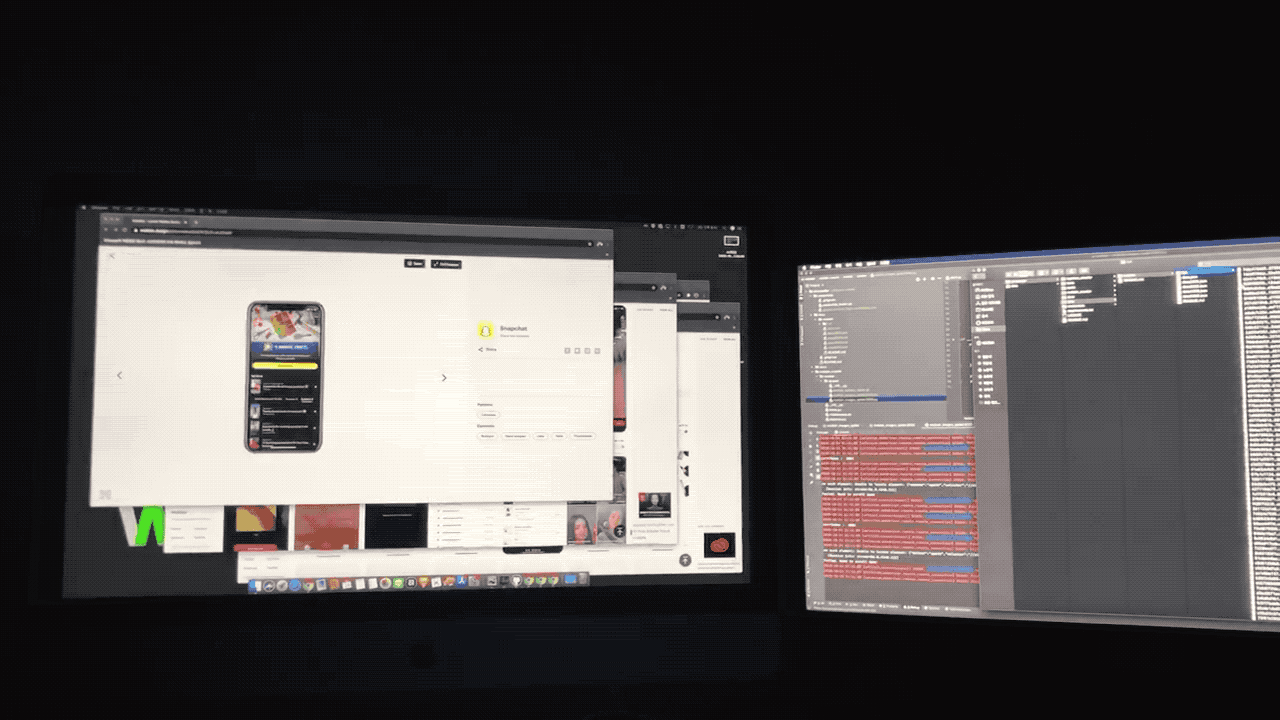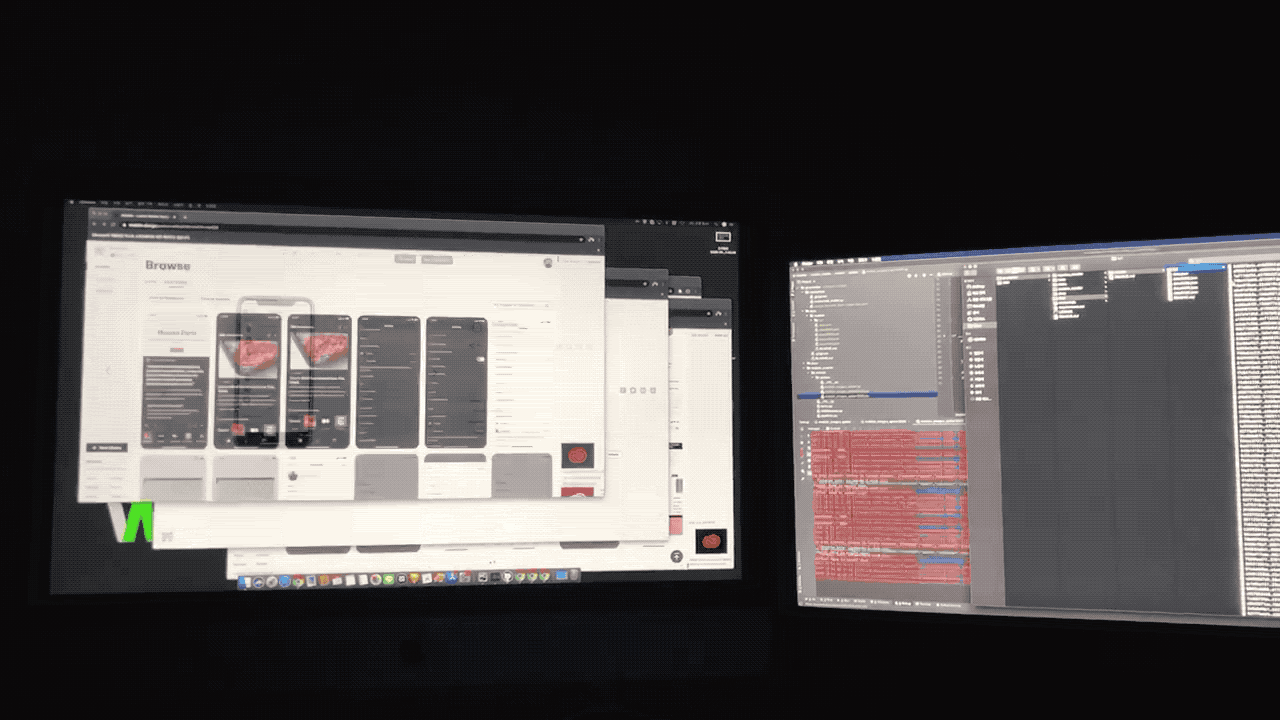
2.데이터 라벨링: SelectStar
Mobbin에서 확보한 스크린샷 데이터를 라벨링하는 과정에서도 큰 행운이 있었습니다. 이 작은 프로젝트가 SelectStar라는 전문 라벨링 플랫폼의 인공지능 데이터셋 지원 프로그램에 선정되어 체계적인 라벨링 지원을 받을 수 있었습니다.
SelectStar는 크라우드소싱 기반의 데이터 라벨링 플랫폼인 Cashmission을 운영하는 한국의 AI 전문회사입니다. SelectStar측에서는 비록 작은 규모지만, 이 프로젝트가 한국의 인공지능 사업 발전에 도움을 줄 수 있을 것이라고 긍정적으로 평가했고, 이 프로젝트에 SelectStar의 Annotation 노하우와 크라우드 소싱 리소스를 제공해줬습니다.

라벨링 과정에서 특히 놀랐던 것은 본격적인 라벨링 작업을 시작하기 전에 가이드 문서를 체계적으로 만드는 것이었습니다.
복잡한 UI 요소를 디자이너나 IT 전문가가 아닌 일반인들이 라벨링한다는 것은 상상만 해도 어려운 일이었습니다. 하지만 SelectStar에서는 전담 프로젝트 매니저를 배정하고, 저와 계속 소통하며 꼼꼼하게 UI라벨링 가이드문서 작성을 하면서 그런 어려움을 극복했습니다.
SelectStar의 노하우와 전문가의 노력으로 만들어진 가이드 문서 덕분에, 복잡한 UI 데이터의 라벨링 작업이 크라우드소싱으로 성공적으로 진행됐고, 그 결과 약 10,000건의 스크린샷을 14개 카테고리로 라벨링한 Annotation 정보를 확보할 수 있었습니다.
3.데이터셋 추가: RICO
다른 한편으로 Google의 연구원인 Bardia Doosti의 소개로 RICO 데이터셋을 알게 됐습니다. RICO는 UNIVERSITY OF ILLINOIS의 DATA DRIVEN DESIGN GROUP에서 여러 논문들에 사용한 데이터셋으로 Bardia 역시 자신이 참여한 UI pattern에 대한 논문에서 RICO 데이터셋을 사용했던 적이 있었습니다.
RICO 데이터셋에는 약 65,000개의 Android 스크린샷과 함께 스크린샷에 대한 방대한 annotation 데이터를 포함되어 있는데, 처음 RICO의 데이터를 확인했을 때는 정말 기뻐서 팔짝팔짝 뛰었습니다. ㅋㅋ
하지만 RICO 데이터셋을 그대로 Object Detection 프로젝트에 사용할 수는 없었습니다. Annotation 데이터의 형식이 TF2와 다르기도 했고, 일부 데이터에서는 아래와 같은 예상치 못한 오류도 있었습니다.
- bounding box(bndbox)가 음수인 경우
- 컴포넌트의 xmax 또는 ymax 값이 스크린샷의 width, height 값보다 큰 경우
- xmin 값이 xmax 보다 크거나 ymin 값은 ymax 보다 큰 경우


저는 수차례 데이터셋의 오류들을 수정하고 또 검증한 끝에 RICO 원본 데이터를 TensorFlow용 `tfrecord` 파일로 만들었습니다. 제가 만든 Python 스크립트는 아래의 gist에서 확인할 수 있습니다.
저와 비슷한 과제를 수행중인 프로젝트에서도 참고하시기 바랍니다.
4. 데이터셋 가공
마지막 데이터 전처리 단계로서, 실제 모델 트래이닝을 시켜보면서 데이터의 문제나 사이즈를 조정하는 작업을… 고통스럽게 반복했습니다. 혹시 필요하신 분들이 있을 것 같아서 제가 사용한 스크립트들은 아래의 저장소에 모아놨습니다 :)
5. TensorFlow 모델 트레이닝

본격적인 트레이팅은 아래의 가이드를 참고해서 Google Colab 환경에서 모델을 만들었습니다. Google Colab에서 제공하는 Free GPU 사이즈에 맞춰서 약 7500 번씩 학습하는 것으로 설정했고, 여러 모델을 테스트했습니다.
보다 상세한 내용은 아래의 Colab 노트북에서 참고할 수 있습니다.
References
- Custom object detection in the browser using TensorFlow.js
- TensorFlow 2 Object Detection API tutorial
- How to Train a TensorFlow 2 Object Detection Model
Training Notebook
6. TensorFlow.JS 모델로 변환해서 사용하기
제가 만들 Zeplin-ML은 웹 브라우저 기반이기 때문에 저는 위 과정을 통해서 만든 TensorFlow모델을 Converter 를 사용해서 Javascript 모델로 변환했습니다.
물론 이 과정에서 정말로 많은 시행착오가 있었지만, 구글의 여러 레퍼런스를 참고해서대부분 해결할 수 있었습니다. 그 중에서도 TFJS에 여러가지 예제를 제공하는 Hugo Zanini의 Github가 큰 도움이 됐기에 아래에 소개합니다. :)
7. Zeplin API와 통합하기
마지막으로 이 머신러닝 모델을 앞서 언급한 Zeplin API 기반의 웹 애플리케이션에 통합했습니다.
Figma나 Sketch 대신에 Zeplin을 선택한 이유는 Sketch, XD, Figma 등 여러 플랫폼을 지원하고, 매우 강력한 API기능이 있다는 점이 매력적이었기 때문입니다. 그리고 실제 개발과정에서 Zeplin. 의 개발자 지원팀에서 Slack과 이메일로 많은 도움을 주었는데.. 이 글을 통해서 감사의 인사를 전합니다.


마치며…
많은 분들의 도움으로 드디어 프로젝트가 눈에 보이는 수준으로 발전했습니다. 이 프로젝트에 직간접 적으로 도움을 주신 모든 분들에게 감사를 드리며 계속해서 더 나은 제품으로 발전 시킬 수 있도록 노력하겠습니다.
